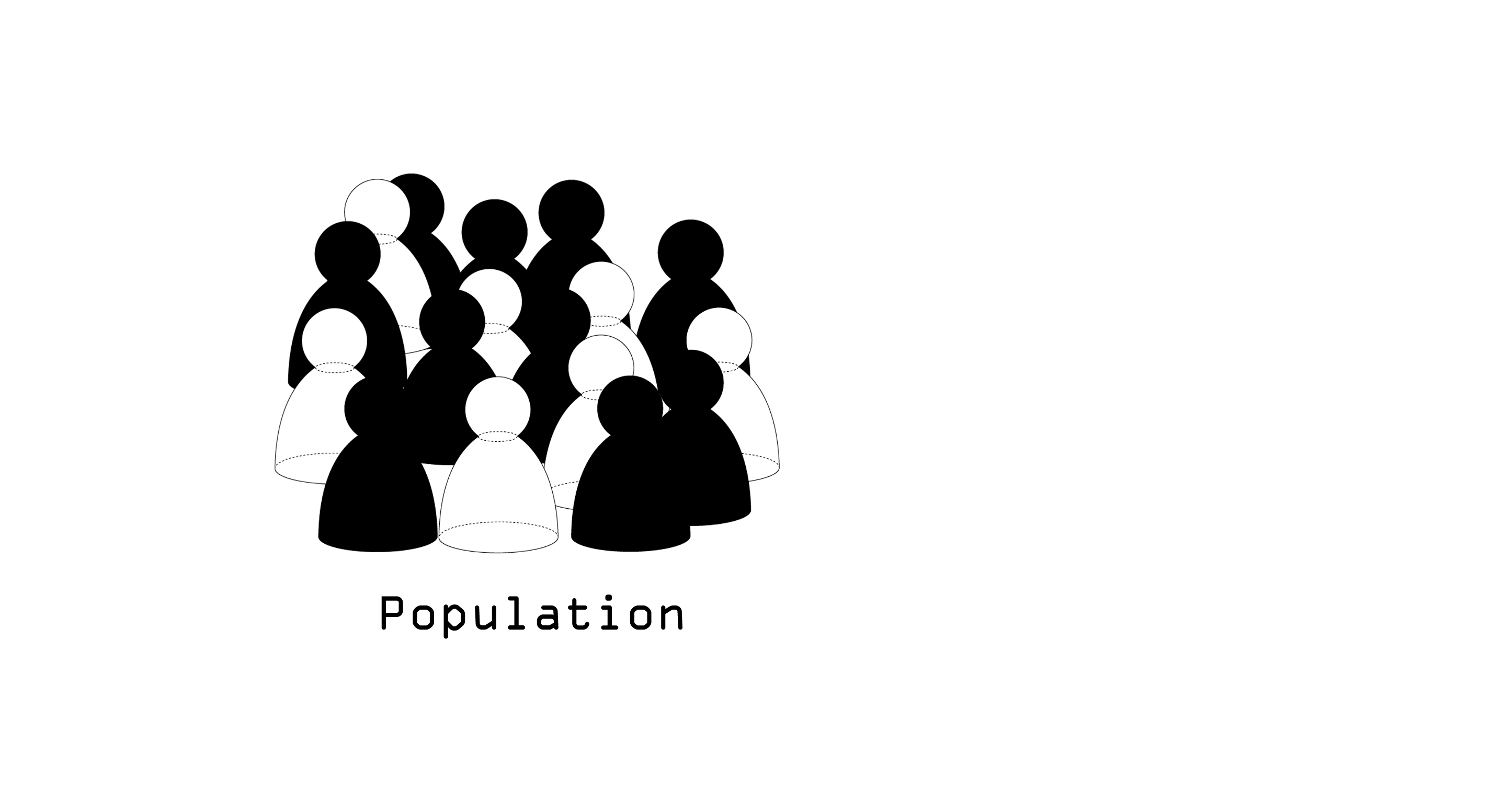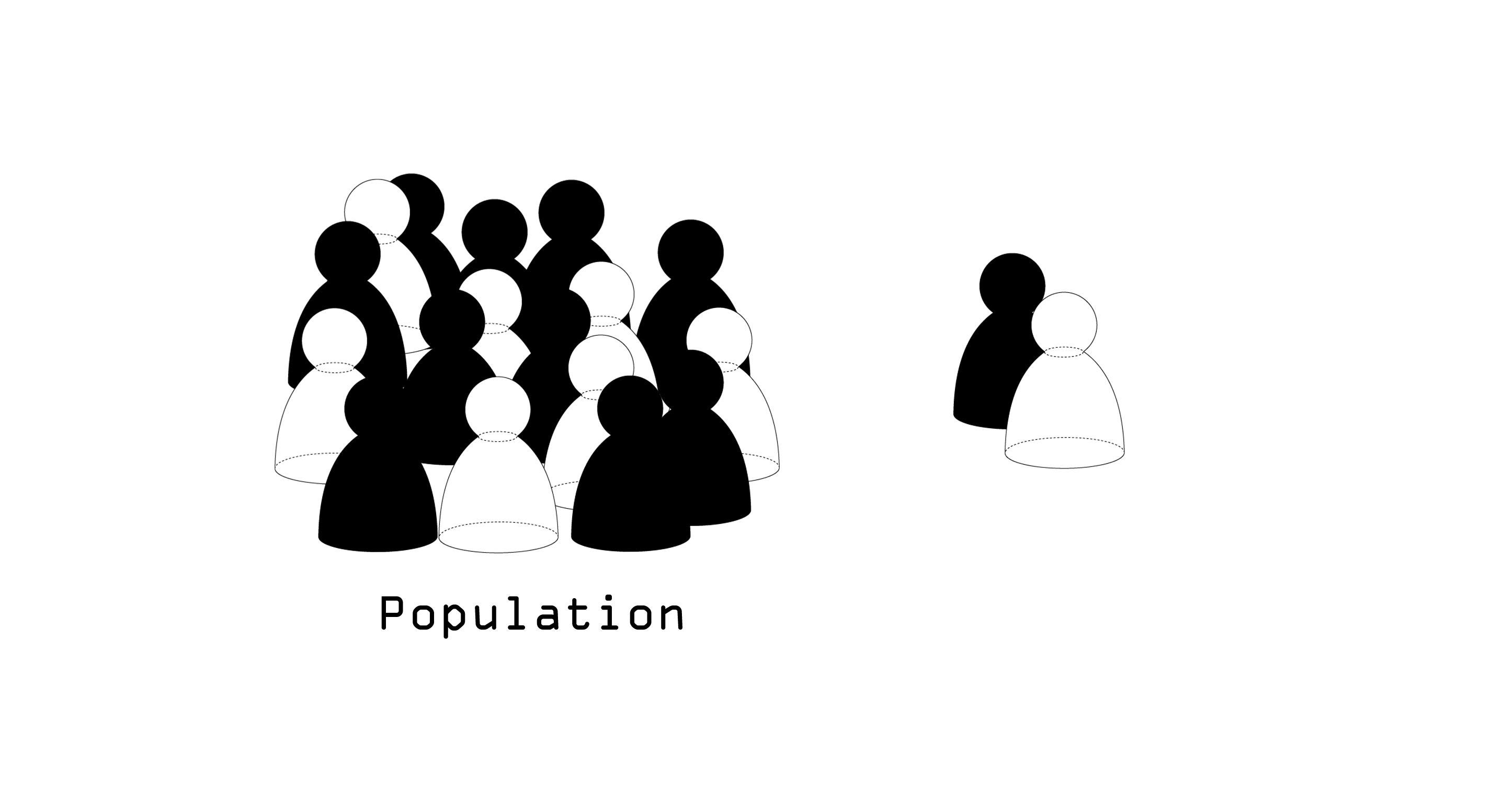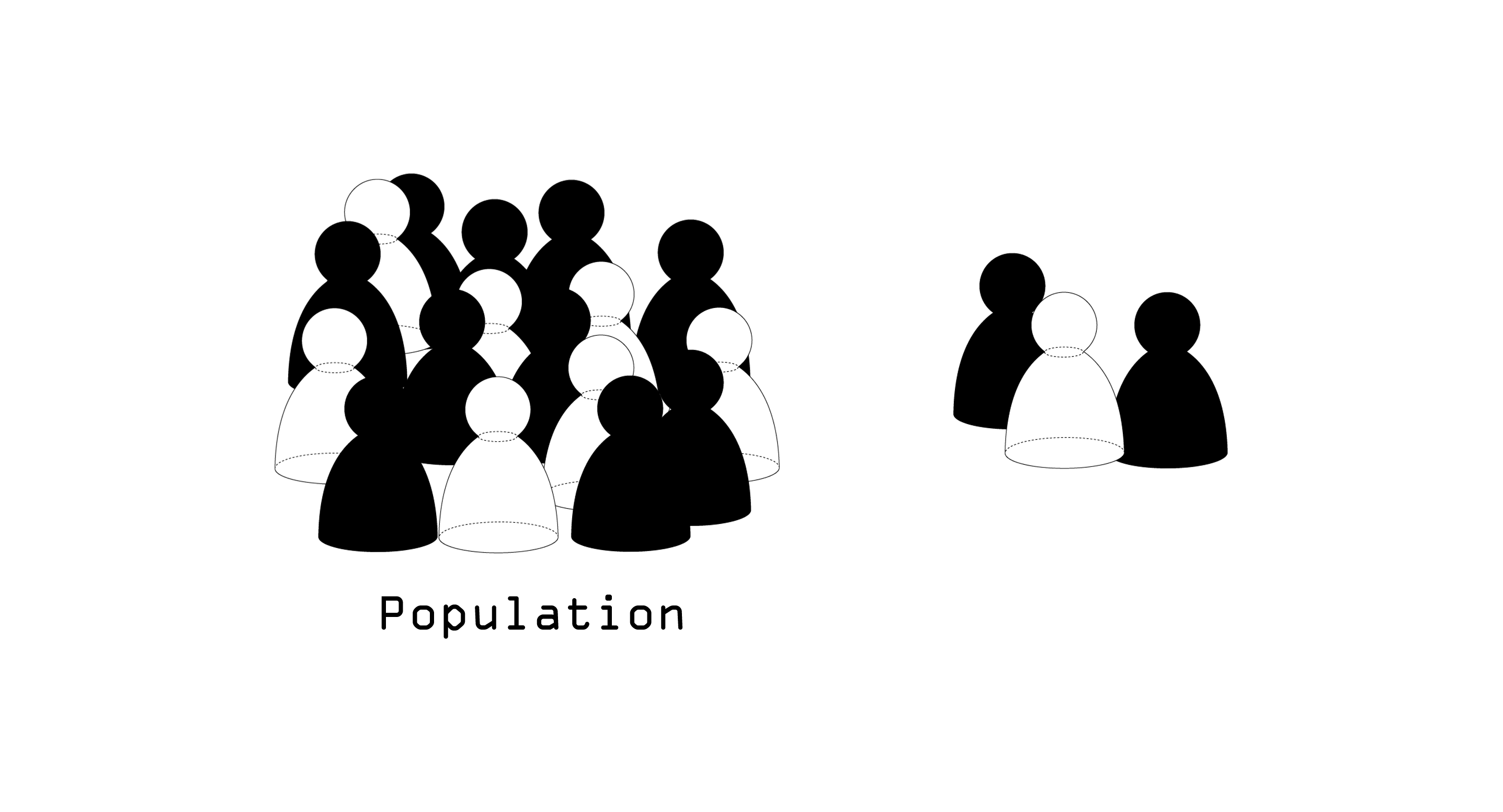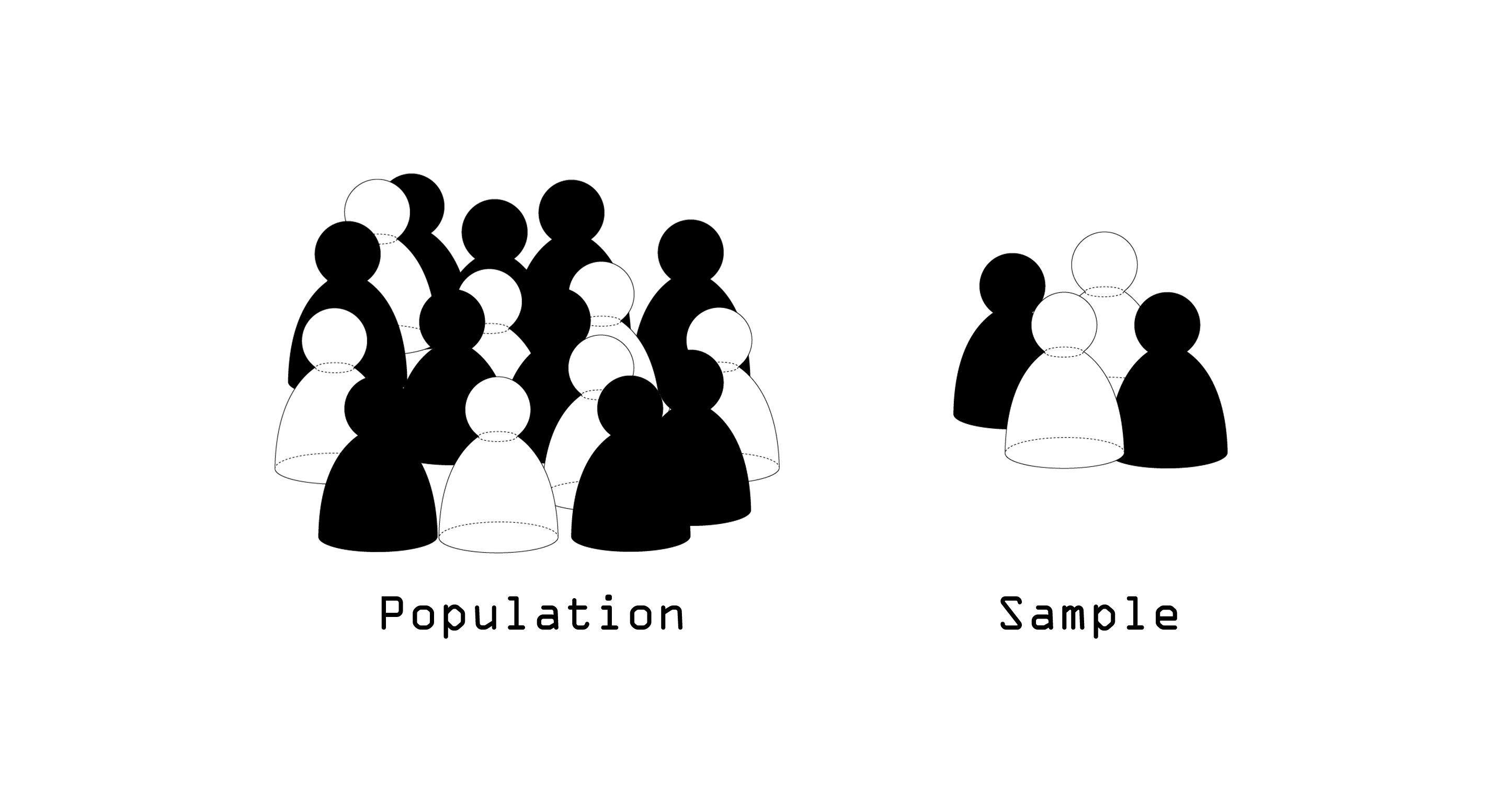O crescente uso de sistemas de inteligência artificial (IA) têm atualmente impacto em várias esferas da
sociedade contemporânea, desde os media online às finanças, política, saúde ou educação, deixando poucas
áreas intocadas. Estes sistemas são, na sua grande maioria, baseados em algoritmos de aprendizagem
automática ou machine learning (ML) que aprendem a tomar decisões com vista a um determinado fim, a
partir de vastos conjuntos de dados de treino. Como tal, o desenvolvimento destas técnicas teve um
crescimento exponencial com a generalização da Internet e expansão das redes sociais. Estes sistemas
tornam-se praticamente ubíquos, alargando o debate sobre as suas implicações na sociedade.
À medida que delegamos capacidades como raciocínio, aprendizagem, reconhecimento de padrões, inferência
ou dedução a estes sistemas, a opacidade inerente à sua complexidade frequentemente obscurece o viés
incorporado nos seus dados de treino ou processos de tomada de decisões.
O projeto “Computer says no” toma por título uma expressão que satiriza esta opacidade, procurando revelar
os vieses ocultos da aprendizagem automática. Desenvolvido como uma narrativa evolutiva e diagramática,
apresentada num website, o projeto decompõe a forma como o viés humano, social e cultural é incorporado
nos conjuntos de dados de treino e amplificado no processo de aprendizagem automática.
Esta abordagem procura promover uma reflexão informada sobre o ciclo "biased data in, biased data out"
na propagação de desigualdades e formas de discriminação social, atendendo a que, como explica Kate
Crawford, “Os dados e conjuntos de dados não são objetivos; são criações de design humano. Damos aos
números a sua voz, deles tiramos inferências, e definimos o seu significado através das nossas
interpretações".
+
All contents extracted from the © respective authors and their works;
only with the purpose of exploratory content manipulation and the creation of new publications & objects -
integrated in an academic experimentation project.
+
Main references:
> https://nooscope.ai/
> https://dl.acm.org/doi/fullHtml/10.1145/3465416.3483305
+
Actual cases of "Human labeling bias" presented:
> "ai is sending people to jail - and getting it wrong - By Karen Hao, 2019"
> "Millions of black people affected by racioal bias in health care algorithms - By Heidi Ledford, 2019"
> "Google apologizes after its Vision Ai produced racist results - By Nicolas Kayser-Bril, 2020"
> "Self-driving cars more likely to drive into black people, study claims - By Anthony Cuthbertson, 2019"
> "healthcare algorithms are biased, and the results can be deadly - ByBen Dickson, 2020"
> "twitter taught microsoft's AI chatbot to be a racist asshole in less than a day - By James Vincent, 2016"
> "why it's totally unsurprising that amazon's recruitment ai was biased against women - By Isobel Asher Hamilton , 2018"
> "algorithms that run our lives are racist and sexist. - By Eliza Anyangwe, 2020"
> "google autocomplete still makes vile suggestions. - By ISSIE LAPOWSKY, 2018"
+
Bias lexicon references:
> [1] https://cpdonline.co.uk/knowledge-base/safeguarding/types-of-bias/
> [2] https://dl.acm.org/doi/fullHtml/10.1145/3465416.3483305
> [3] https://onlinelibrary.wiley.com/doi/abs/10.1002/%28SICI%291520-6807%28199604%2933%3A2%3C143%3A%3AAID-PITS7%3E3.0.CO%3B2-S
> [4] https://en.wikipedia.org/
+
!! Not optimized for safari, please use another browser !!
AUTHOR
Marco Alpoim
PROJECT ADVISORS
Prof. Luísa Ribas
Prof. Pedro Ângelo
DISCIPLINES
Project II
Laboratory II
Master's in Communication Design
Faculty of Fine Arts, University of Lisbon
2021/2022
SPECIAL THANKS
Alexandra Guimarães
Beatriz Querido
Pedro Pereira